
I. Introduction
Automatic data generation using artificial intelligence (AI) has attracted significant attention from the research community [1], [2]. Deep learning (DL) models have demonstrated superiority in processing complex, unstructured data, such as images, text, audio, and social media data due to their multilayer non-linear architectures [3], [4]. AI-generated images can simulate real ones with high fidelity, allowing attackers to breach authentication systems on AI and DL technologies using even minimal amounts of fake data [5].
AI systems are typically vulnerable to attacks, from data collection to deployment. According to Gartner, 30% of cyberattacks will involve data poisoning, model theft, or adversarial attacks on machine learning models by 2025 [6]. This vulnerability appears to have been unforeseen, and 25 of 28 organisations surveyed lack strategies to protect their AI systems [7]. To address these vulnerabilities and improve understanding of associated risks, researchers focus on four key areas: (i) attack identification (risk assessment), (ii) defence mechanisms (threat mitigation), (iii) robustness evaluation, and (iv) novel applications.
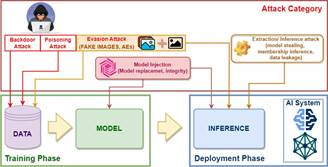
Fig 1. The Life Cycle of Deep Learning Model Development and Potential adversarial Threats at Each Stage
Figure 1 illustrates the development and deployment lifecycle of AI models, highlighting adversarial threats corresponding to the capabilities of attackers. The lifecycle is divided into two phases: the training phase (data collection, preprocessing, model selection, parameter tuning, optimisation, and validation) and the deployment phase (post-training model execution with fixed architecture and parameters).
- Attacks in training phase: Attacks in the training phase assume the ability to manipulate training data to degrade or harm the resulting model, often by collecting noisy data from extenal sources. Specifically, the memorisation effectiveness of DL models can be exploited as a security flaw [8], note that “data poisoning” encompasses both poisoning and backdoor attacks, although their objectives differ.
- Attacks in deployment phase: The goal of deployment phase attacks is to identify a “similar” sample T(x) of x such that the fixed model fθ will avoid its prediction from the original “ground truth” label y. The evasion conditions can be separated into two cases:
- Untargeted attacks: where fθ (x) = y but fθ (T(x)) != y, or
- Targeted attacks: where fθ (x) = t but fθ (T(x)) != y, t != y.
Such T(x) is known as an adversarial example of x [9] and can be understood as an out-of-distribution sample or generalization error [10].
The effectiveness of deep learning models depends on the amount of data and computational power. The more training data, the higher the accuracy of the model [11]. Distributed computing optimizes multiple data sources but requires data sharing, which can raise privacy concerns [12]. Therefore, privacy in machine learning, especially deep learning, is increasingly prioritized in research, including from major companies like Google, Apple, and Microsoft.
Nowadays, there are various research groups that have developed datasets to test and evaluate AI systems using DL models, such as CASIA-FASD [13], FaceForensics++ [14], MFC2018 [15], and DFDC [16], which support adversarial testing. These datasets include millions of images/videos generated via various techniques (e.g. deepfakes) and are evaluated using metrics like PSNR and SSIM. These datasets support many DL models and cover numerous scenarios and forgery techniques, all publicly available with detailed research guidelines.
This paper introduces Hybrid CUB, a dataset that combines real images from CUB-200-2011 [17] with synthetic images generated using GAN methods [18], aiming to support the evaluation of authentication systems based on deep learning models and to enrich AI training data.
The exclusive use of the CUB-200-2011 dataset is a deliberate choice, grounded in its relevance to the research objectives and the need for controlled model evaluation. As a widely adopted benchmark in fine-grained image classification, particularly in deep learning contexts, CUB-200-2011 offers a rich set of 200 bird species with high-resolution and well-annotated images. This level of granularity allows for robust performance assessment without requiring additional datasets.
Furthermore, relying on a single dataset ensures consistency and reduces potential biases that could emerge from combining datasets with varying structures, image qualities, or labeling standards. Although expanding to other datasets could improve model generalizability, it would also introduce challenges in preprocessing, hyperparameter tuning, and result interpretation. To maintain clarity, focus, and experimental control, this study strategically confines its scope to the CUB-200-2011 dataset.
The paper is structured as follows: Section 2 describes the proposed dataset in detail, the image collection process, and data processing. Section 3 presents experiments with the dataset to detect fake images. Section 4 concludes and proposes future research directions.
II. Proposed Hybrid CUB Dataset for Deep Learning Model Evaluation
A. Overview of the dataset
The Hybrid CUB dataset contains 30,000 images in three sizes (256256, 128
128, and 64
64 pixels). Each size folder includes 10,000 images, with 5,000 real images from CUB-200-2011 and 5,000 fake GAN images generated [18]. It was constructed and evaluated through a four-step process:
- Step 1. Training the GAN model: First, the GAN model was trained using the CUB-200-2011 dataset. This is a typical dataset for bird image recognition and classification research, developed by researchers from Caltech and UCSD, which includes 11,788 images of 200 different bird species. Each image is labelled in detail with the species name and attributes, such as colour, pattern, and body parts.
- Step 2. Generating fake data: After training the GAN, descriptions of each subclass in the CUB-200-2011 dataset were used to generate the corresponding fake images with the specified characteristics.
- Step 3. Evaluating data quality: The quality of the generated images was evaluated using the PSNR metric, comparing the differences with the original images. Higher PSNR values indicate better reproduction quality, and then their average value was calculated for the entire dataset.
- Step 4. Collecting original images and combining with GAN-generated images: The original images corresponding to the selected classes were collected and combined with the fake images generated from the GAN model to create a complete dataset.
Specific details of these steps can be found in [18]. Figure 2 visually displays some images from the Hybrid CUB dataset.

Fig 2. Some images from the Hybrid CUB dataset arranged in pairs ‘real image – fake image’ from left to right (top: 256×256 pixels, middle: 128×128 pixels, bottom: 64×64 pixels)
B. Image Normalisation Algorithm and Data Labelling Convention
1) Image Normalization Algorithm
Since images from the CUB-200-2011 dataset have inconsistent sizes, so their sizes must be normalized to squares with 3 dimensions: 256×256, 128×128 and 64×64 pixels to match the sizes of the fake image set. We propose Algorithm 1 with 4 steps as follows:
Algorithm 1: Image Preprocessing – Size Normalization
Step 1. Determine the center of the image:
xcenter = [image width/2]
ycenter = [image height/2]
Step 2. Determine the size of the square:
If (image height > image width), then:
a = image width /* a is the square edge length */
Else:
a = image height;
Step 3. Calculate the coordinates of the square
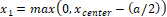
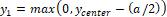
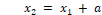
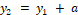
Step 4. Crop and resize the image
Crop the image into a square according to coordinates x1, y1, x2, y2. Resize the image to 256×256, 128×128 and 64×64 pixels, respectively.
2) Image Labelling Convention
All images in the dataset are labelled for convenience in identification after shuffling, depending on the specific problem. We follow the labelling convention for images in the dataset as follows: ‘x_ y_ id_ px.jpg’ where:
- x: class value from 1 to 8 as defined in Table I.
- y: equals 0 if it is a real image, otherwise equals 1.
- id: the sequential number of the image in each image folder.
- px: the size of the image.
C. Image Collection and Data Splitting
After size normalization using Algorithm 1, the images were organized into folders according to the size (eg, 256×256 pixels), each containing three subfolders: train (training), val (validation), test (testing). In these subfolders, real images from CUB-200-2011 were placed in the subfolder ‘0’ and GAN- generated fake images in ‘1’. All images are labelled according to the convention described above. Image selection followed Step 4 in the four-step process presented in Section 2.1, with quantities specified in Table I.
Table I. Quantity of images in Hybrid CUB Dataset (same counts across all sizes)
| Class | CUB-200-2011 Species | Train | Validation | Test | |||
| CUB | GAN | CUB | GAN | CUB | GAN | ||
| 1 | American_Goldfinch | 48 | 572 | 6 | 72 | 6 | 72 |
| 2 | Bay_Breasted_Warbler | 48 | 571 | 6 | 71 | 6 | 71 |
| 3 | Cardinal | 45 | 571 | 6 | 71 | 6 | 71 |
| 4 | Great_Crested_Flycatcher | 48 | 571 | 6 | 71 | 6 | 71 |
| 5 | Lazuli_Bunting | 46 | 571 | 6 | 71 | 6 | 71 |
| 6 | Rock_Wren | 48 | 572 | 6 | 72 | 6 | 72 |
| 7 | Summer_Tanager | 48 | 572 | 6 | 72 | 6 | 72 |
| 8 | Other | 3,669 | 0 | 458 | 0 | 458 | 0 |
| Total | 4,000 | 4,000 | 500 | 500 | 500 | 500 | |
D. Evaluation, Application, and Comparison with Other Datasets
The proposed dataset was compared with the original CUB-200-2011 dataset. The PSNR index, used to measure the fidelity of fake images compared to real images, achieved an average of 29.65 throughout the set [18]. Furthermore, we compared our dataset with several widely used datasets such as CASIA-FASD, DFDC, MFC2018, FaceForensics++, as shown in Table II.
Table II. Comparison with some Datasets Applied in AI
| Dataset | Quantity | Source | Generation technique | Evaluation Index | Application |
| CASIA-FASD [13] | ~50,000 images | 500 subjects | Print, LCD, 3D | PSNR, SSIM | DL models |
| FaceForensics++ [14] | Millions images/videos | Diverse subjects | facial simulation, deepfake | PSNR, SSIM | DL models |
| MFC2018 [15] | Thousands of images/videos | Multiple sources | Multiple Techniques | PSNR, SSIM | DL models, anti-spoofing solutions |
| DFDC [16] | Millions of images/videos | Multiple sources | Advanced deepfakes | PSNR, SSIM | DL models, deepfake detection algorithms; |
| Hybrid CUB | 30,000 images | CUB-200-2011 + GAN | GAN [18] | PSNR | DL models |
The proposed Hybrid CUB dataset can be used to evaluate the performance and reliability of object classification models, test the accuracy and robustness of DL models. Additionally, it can also be a supplementary data source in the training process, helping to improve the capabilities of DL models in AI systems.
III. Dataset Experiments and Results
Experiments were conducted using Python 3, PyTorch 2.3.1, and CUDA 12.1 on Google Colab with a T4 GPU (16GB VRAM). The dataset was divided according to Table I for model training and testing experiments. We selected 4 popular DL models for object classification: ResNet-50 [19], MobileNetV2 [20], ShuffleNetV2 [21], and VGG19_bn [22]. All models used pre-trained configurations on the PyTorch platform and were trained with 100 epochs.
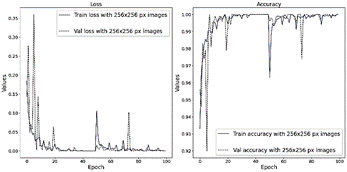
Fig 3. Training chart of ResNet-50 model after 100 epochs using 256×256 pixel images
Figure 3 illustrates the training results of the ResNet-50 model in loss and accuracy indexes with the proposed Hybrid CUB dataset, using images of size 256256 pixels. Model evaluation indices, including Loss, Accuracy, Precision, and Recall [23], were applied to evaluate performance. The training results of the DL models are shown in Table III.
Table III. Training results of 4 deep learning models on the hybrid CUB dataset (accuracy, precision, recall values are calculated in %)
| Model | Size | Loss | Accuracy | Precision | Recall |
| ResNet-50 [19] | 64×64 | 0.0028 | 99.91 | 99.91 | 99.91 |
| 128×128 | 0.0007 | 99.98 | 99.98 | 99.98 | |
| 256×256 | 0.0003 | 99.99 | 99.99 | 99.99 | |
| MobileNetV2 [20] | 64×64 | 0.0000 | 100.00 | 100.00 | 100.00 |
| 128×128 | 0.0015 | 99.91 | 99.91 | 99.91 | |
| 256×256 | 0.0002 | 100.00 | 100.00 | 100.00 | |
| ShuffleNetV2 [21] | 64×64 | 0.0007 | 99.95 | 99.95 | 99.95 |
| 128×128 | 0.0000 | 100.00 | 100.00 | 100.00 | |
| 256×256 | 0.0000 | 100.00 | 100.00 | 100.00 | |
| VGG19_bn [22] | 64×64 | 0.0026 | 99.20 | 99.30 | 99.20 |
| 128×128 | 0.0087 | 99.78 | 99.78 | 99.78 | |
| 256×256 | 0.0065 | 99.82 | 99.83 | 99.83 |
Table III shows that all models achieved good convergence when using our dataset. Additionally, we also evaluated the accuracy of the models to detect fake images. In practice, attackers often attack systems by mixing a small proportion of fake data into the input dataset. We experimented with 1,000 images from the dataset containing 3%, 5%, and 10% fake data, respectively. Images were randomly selected and different in each experiment. The experimental results show that the models achieved high accuracy rates in detecting fake images (Detailed results in Table IV).
Table IV. Evaluation of the accuracy of the deep learning model (%) performed with 1,000 random images
| Real : Fake | Size | ResNet-50 | MobileNetV2 | ShuffleNetV2 | VGG19_bn | ||||
| Real | Fake | Real | Fake | Real | Fake | Real | Fake | ||
| 97% Real : 3 % Fake | 64×64 | 99,90 | 100 | 100 | 100 | 99,91 | 100 | 100 | 100 |
| 128×128 | 99,69 | 100 | 100 | 100 | 99,98 | 100 | 99,9 | 100 | |
| 256×256 | 100 | 100 | 100 | 100 | 99,99 | 100 | 100 | 100 | |
| 95% Real : 5 % Fake | 64×64 | 99,68 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| 128×128 | 99,89 | 100 | 100 | 100 | 99,91 | 100 | 100 | 100 | |
| 256×256 | 99,89 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | |
| 90% Real : 10 % Fake | 64×64 | 99,56 | 99,89 | 100 | 100 | 99,95 | 99,00 | 100 | 100 |
| 128×128 | 99,67 | 99,89 | 100 | 100 | 100 | 100 | 99,78 | 100 | |
| 256×256 | 100 | 100 | 100 | 100 | 100 | 100 | 99,89 | 100 | |
The results of Table IV show that the experimental models with the proposed dataset achieve high performance in identifying fake images. Specifically, some models achieve 100% accuracy in detecting fake images. The DL models applied in the experiments are all advanced and modern methods that are widely used in the current research community.
IV. Conclusions
In this study, we emphasise the critical role of data in AI and introduce Hybrid CUB, a novel dataset designed for testing DL models. Binary classification experiments with two classes ‘0’ (real images) and ‘1’ (fake images) show that this dataset is suitable to evaluate the ability to detect fake images in AI-based authentication systems. The dataset can improve the accuracy and robustness of DL models against attacks on AI systems. We also compared the Hybrid CUB dataset with CUB-200-2011 along with several other datasets in the same field and evaluated fidelity through the PSNR index.
In future works, we will develop larger datasets using similar methodologies to create more diversity than the original dataset. We will also experiment with multiclass, multiobject, and multilabel datasets, not limited to just two classes ‘0’ and ‘1’. This will provide additional data sources for the training process, supporting enhancing the performance of many other DL models.
References
- A. Ara, M. S. Alam et al., “A comparative review of ai-generated image detection across social media platforms,” Global Mainstream Journal of Innovation, Engineering & Emerging Technology, Vol. 3, No. 01, pp. 11-22, 2024.
- A. Biswas, N. Md Abdullah Al, A. Imran, A. T. Sejuty, F. Fairooz, S. Puppala, and S. Talukder, “Generative adversarial networks for data augmentation,” in Data Driven Approaches on Medical Imaging, Springer, pp. 159-177, 2023.
- I. Goodfellow, Y. Bengio, A. Courville, “Deep Learning,” MIT Press, http://www.deeplearningbook.org, 2016.
- A. Charu C, Neural networks and deep learning: a textbook. Springer, 2018.
- D. Gragnaniello, F. Marra, and L. Verdoliva, “Detection of ai-generated synthetic faces,” in Handbook of digital face manipulation and detection: From deepfakes to morphing attacks. Springer International Publishing, Cham, pp. 191-212, 2022.
- Wymberry, Conor, and Hamid Jahankhani, “An Approach to Measure the Effectiveness of the MITRE ATLAS Framework in Safeguarding Machine Learning Systems Against Data Poisoning Attack,” Cybersecurity and Artificial Intelligence: Transformational Strategies and Disruptive Innovation. Cham: Springer Nature Switzerland, pp. 81-116, 2024.
- LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton, “Deep learning,” Nature, Vol. 521, No.7553, pp. 436-444, 2015.
- Zhang, Chiyuan, et al., “Understanding deep learning (still) requires rethinking generalization,” Communications of the ACM, Vol. 64, No. 3, pp. 107-115, 2021.
- Biggio, Battista, et al. ‘Evasion attacks against machine learning at test time,” Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2013, Prague, Czech Republic, September 23-27, 2013, Proceedings, Part III 13, Springer Berlin Heidelberg, pp. 387-402, 2013.
- I. J. Goodfellow, J. Shlens, and C. Szegedy, ‘Explaining and Harnessing Adversarial Examples,” CoRR, Vol. 1412, No. 6572, 2015.
- Florian Tramer, Nicholas Carlini,Wieland Brendel, and Aleksander Madry, “On adaptive attacks to adversarial example defenses,” Advances in neural information processing systems, Vol. 33, pp. 1633-1645, 2020.
- C. C. Aggarwal, “Neural Networks and Deep Learning,” Springer, Vol. 10, No. 978, 2018.
- Tang, Yan, et al., “Fusing multiple deep features for face anti-spoofing,” In: Biometric Recognition: 13th Chinese Conference, CCBR 2018, Urumqi, China, August 11-12, 2018, Proceedings 13. Springer International Publishing, pp. 321-330, 2018.
- Rossler, Andreas, et al., “Faceforensics++: Learning to detect manipulated facial images,” In: Proceedings of the IEEE/CVF international conference on computer vision, 2019. p. 1-11..
- Verdoliva and Luisa, “Media forensics and deepfakes: an overview,” IEEE journal of selected topics in signal processing, Vol. 14, No. 5, pp. 910-932, 2020.
- Dolhansky, Brian, et al. “The deepfake detection challenge (dfdc) dataset,” arXiv preprint arXiv:2006.07397, 2020.
- C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie, “The caltech-ucsd birds-200-2011 dataset,” Technical Report CNS-TR-2010-001, California Institute of Technology, 2011.
- T. P. Ho, P. D. Trung, and B. T. Lam, “A novel generalized adversarial image method using descriptive features,” Journal of Science and Technology on Information security, pp. 63-76, 2023.
- Koonce, Brett, and Brett Koonce, ‘ResNet 50’, Convolutional neural networks with swift for tensorflow: image recognition and dataset categorization, Springer, pp. 63-72, 2021.
- M. Sandler et al., “Mobilenetv2: Inverted residuals and linear bottlenecks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4510-4520, 2018.
- Y. Martindez-Diaz et al., “Shufflefacenet: A lightweight face architecture for efficient and highly-accurate face recognition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pp. 2721-2728, 2019.
- M. Shaha and M. Pawar, “Transfer learning for image classification,” in 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), pp. 656-660, 2018.
- Juba, Brendan, and Hai S. Le, “Precision-recall versus accuracy and the role of large datasets,” Proceedings of the AAAI conference on artificial intelligence, Vol. 33, No. 01, pp. 4039-4048, 2019.